
This post will describe how I moved my basic collection of apps on my Raspberry Pis from a single node Docker based container environment to Kubernetes. At first glance this shouldn't be too big of an endeavor, right? It kind of is if you don’t know what to look for. But first, let's clarify the why. Why move a perfectly fine, relatively simple solution to something else that of does the same thing?
The biggest factor was Learning. I figured that I have a good grasp of Docker and Docker Swarm since I have been using it at work for quite some time now. However, with the questionable future of Docker Swarm, it seemed like a natural progression to get towards Kubernetes.
Another point is the unification of configuration. Whereas in my Docker environment I hat multiple points where I would schedule my containers, multiple points where my data would be and multiple tools which I had to configure (e.g., traefik). Kubernetes solves almost all of this by unifying everything into a single API, from storage to networking and deployment of the containers.
Technicalities
I'll be using some different technologies in this post namely there is:
ansible, as the overarching automation tool
Kubernetes
Helm, to deploy predefined applications to my cluster
I use the following alias alias k=kubectl for brevity.
Later on in this post I’ll be using ansible to deploy k8s objects utilizing the kubernetes.core module
To do this there are two options, the ansible native way:
- name: create namespace
kubernetes.core.k8s:
name: testing
api_version: v1
kind: Namespace
state: present
and the other option is to basically write a kubernetes manifest into the definition field:
- name: create namespace
kubernetes.core.k8s:
state: present
definition:
api_version: v1
kind: Namespace
metadata:
name: testing
these two versions basically yield the exact same result. Which leaves it up to personal preference what to use. For this post I'll be sticking to the second choice. Since it's easier to extract the manifest if you do not want to use ansible.
The complete cluster preparation is contained in an ansible playbook you can find in my github repository.
Before the script can run successfully there are some prerequisites that have to be met:
a control node with a somewhat current ansible version (>2.10)
the kubernetes.core collection for ansible, it can be installed via
sh ansible-galaxy collection install kubernetes.coreon the control nodeansible needs to be able to reach all our nodes and login to them via SSH, there are some pointers in the Building an inventory section
the user ansible uses to login needs to be able to gain root privileges, either set
NOPASSWDin the sudoers file or add the--ask-sudo-passwordoption to the playbook execution
Cluster
Before we can look at our application and how to move it, we have some foundation we have to set up. This process is however not limited to this environment. The application part later on will most likely work with any other Kubernetes flavour or even managed Kubernetes services like EKS, AKS and GKE.
My environment consists of the following (physical) machines:
1 Raspberry Pi 3 Model B+ running Raspbian on a 32 Bit armv7l Kernel
1 Raspberry Pi 4 Model B running Raspbian on a 64 Bit aarch64 Kernel
1 Notebook with 4c/8t, 8 GB RAM running Ubuntu Server 21.10
1 QNAP NAS serving a NFS share
What's noteworthy about this setup is that we have a mix of CPU architectures. While the Raspberry Pis are ARM based the notebook is more classically x86_64. This is not a problem per se, but we'll have to consider it later on when we are choosing the images we want to base our containers on. I made sure for my setup, that the Raspberry Pis are running a 64-Bit Kernel. This might be necessary in the future if we want to use more advanced networking with cilium.
The first decision to be made is the selection of what flavor of kubernetes to use. Since theres an
There are a handful of factors which influence this selection. First of all, our construct is somewhat resource constrained, and it offers no autoscaling capabilities which we would have in Private/Public Cloud environments.
The next consideration is simplicity. The later parts of this post where we talk about in-cluster resources and mechanisms which are supposed to provide value independently of the readers background. Be it someone who just wants to learn, or a DevOps Engineer in an enterprise context who got the task of migrating some old apps to their EKS/AKS/GKE deployment.
Considering these points i chose k3s since it fits the criteria.
it's resource-efficient, since it's focused on IoT use-cases
it's easy to deploy using their setup script
it comes with sane defaults for storage, networking
it conveniently installs some utilities like kubectl and crictl
Building an inventory
Let's begin with an overview overview of the machines in our cluster. well separate them into two groups, servers and agents according to the k3s naming.
The resulting inventory file looks like this in ansible ini form:
[k3s:children]
k3s-server
k3s-agent
[k3s-server]
druid ansible_host=druid.localdomain HEALTHCHECK_HOOKURL=xxx1
[k3s-agent]
monkeyrocket ansible_host=monkeyrocket.localdomain HEALTHCHECK_HOOKURL=xxx2
whitebox ansible_host=whitebox.localdomain HEALTHCHECK_HOOKURL=xxx3
This allows us to reference servers/agents separately or all the machines as a whole, depending on what our following scripts are supposed to accomplish. Another option of the inventory file gives us is to set arbitrary variables like the HEALTHCHECK_HOOKURL, we'll talk about it a bit later in this post.
If you are curious where the names come from, I chose to set all my device hostnames after NSA Surveillance tools.
Building the cluster
At this point we are ready to get started setting up our cluster. k3s provides us with a handy setup script. which simplifies our deployment immensely.
Initializing the cluster
To begin initializing the cluster we fetch the k3s-install script and run it, passing in our installation options via environment variables.
In this case I bring the port range k3s can use down to start from 1000, since I need some lower ports for my services.
- name: get the installer script
ansible.builtin.get_url:
url: https://get.k3s.io
dest: /root/k3s.sh
mode: '0500'
- name: run the installer script
ansible.builtin.command: sh k3s.sh
args:
chdir: /root
creates: /var/lib/rancher/k3s/server/node-token
environment:
INSTALL_K3S_EXEC: "--service-node-port-range 1000-32767"
When this is done successfully, we read a token from the server-node. This token will be used subsequently to join agent nodes to the cluster.
Notice that the ansible.builtin.slurp module returns base64 encoded content and thus we have to decode it using the b64decode filter.
- name: get cluster token
ansible.builtin.slurp:
src: /var/lib/rancher/k3s/server/node-token
register: node_token_raw
- set_fact:
node_token: "{{ node_token_raw['content'] | b64decode | trim }}"
Joining agents to the cluster
Now that everything on the cluster side of things is set up, we can continue adding the agent nodes.
To start the process, we need to download the k3s install script like we did on our server. The execution of the script also largely stayed the same. We just need to add two Environment variables, K3S_URL and K3S_TOKEN. The URL points to our server nodes hostname. We can access it by looking into our k3s-server group we defined in our ansible inventory. The second value, the join token, can be accessed via ansible hostvars we set in the previous play while initializing the cluster.
- name: get the installer script
ansible.builtin.get_url:
url: https://get.k3s.io
dest: /root/k3s.sh
mode: '0500'
- name: run join script
ansible.builtin.command: sh k3s.sh
args:
chdir: /root
environment:
K3S_URL: "https://{{ groups['k3s-server'] | first }}:6443"
K3S_TOKEN: "{{ hostvars[groups['k3s-server'] | first]['node_token'] }}"
Updating nodes
One open point in regards to the nodes still remains. The patching of the base OS. There are some approaches which might be discovered in future blog posts.
Rancher System Upgrade Controller: https://github.com/rancher/system-upgrade-controller (k8s)
Ansible from cronjobs (ansible)
Ansible from AWX (ansible)
unattended-upgrades (apt)
Monitoring
At this point we probably want to know when things go wrong so we can react to it. My environment does not currently have any established monitoring solution like Prometheus, ELK Stack or PRTG. I have opted for a simple solution utilizing healthchecks.io. There is a free offering which allows me to "monitor" 20 different entities. It works by receiving a webhook at a specified time and alerting if the hook is not called within a certain grace period.
The service has a free tier but if you need scale or prefer a selfhosted solution, you can use the OSS Project to get the same functionality on your own infrastructure.
The monitoring is implemented as CronJobs which are bound to specific nodes, which looks like this in the ansible script:
- hosts: k3s
gather_facts: false
vars_files:
- variables.yml
tasks:
- name: deploy healthchecks
kubernetes.core.k8s:
state: present
kubeconfig: "{{ KUBECONFIG }}"
definition:
apiVersion: batch/v1
kind: CronJob
metadata:
name: "{{ inventory_hostname }}-healthcheck"
namespace: default
spec:
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
schedule: "*/5 * * * *"
jobTemplate:
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: "{{ inventory_hostname }}"
containers:
- name: curlimage
image: curlimages/curl
imagePullPolicy: IfNotPresent
command:
- sh
- -c
args:
- curl $SERVICE_URL
env:
- name: SERVICE_URL
value: "{{ HEALTHCHECK_HOOKURL }}"
restartPolicy: OnFailure
delegate_to: "{{ groups['k3s-server'] | first }}"
It looks like there is a lot going on, so let’s break it down a bit. We run a play on all nodes in the cluster hence the hosts: k3s. But by delegating the play to a server via delegate_to: "{{ groups['k3s-server'] | first }}" we do all the actions on a server node which has a kubeconfig and thus permissions to create objects in the cluster.
The created object is a simple Cronjob, bound to a specific node via a Node Selector whose purpose is to call the health check URL. This is also the point where the health check URL from the inventory file is used.
kwatch
The Health Checks we just created tell us something about nodes, but what about stuff that happens in the cluster? For this i use another simple tool called kwatch. Kwatch is deployed inside the cluster and watches for error events. In case of an error it posts a message to many different messaging solutions like slack, telegram or Microsoft teams. The deployment looks like this:
- name: Ensure the kwatch namespace is present
kubernetes.core.k8s:
kubeconfig: "{{ KUBECONFIG }}"
definition:
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
- name: Ensure the ConfigMap is present
kubernetes.core.k8s:
kubeconfig: "{{ KUBECONFIG }}"
definition:
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
maxRecentLogLines: 50
ignoreFailedGracefulShutdown: true
alert:
telegram:
token: "{{ TELEGRAM_TOKEN }}"
chatId: "{{ TELEGRAM_CHATID }}"
- name: Ensure the deployment manifest is present
ansible.builtin.get_url:
url: "https://raw.githubusercontent.com/abahmed/kwatch/{{ KWATCH_VERSION }}/deploy/deploy.yaml"
dest: /root/kwatch_deploy.yaml
mode: "0664"
- name: Ensure the Deployment manifest is deployed
kubernetes.core.k8s:
kubeconfig: "{{ KUBECONFIG }}"
state: present
src: /root/kwatch_deploy.yaml
It creates a namespace, a config map and the kwatch deployment.
To check if kwatch is working correctly we can create a test pod to see if the notifications are working. My Test pod looks like this:
---
apiVersion: v1
kind: Pod
metadata:
name: termination-demo
namespace: default
spec:
containers:
- args:
- -c
- sleep 5
- echo "im doing stuff"
- terraform init # This will fail because terraform is not installed
command:
- /bin/sh
image: alpine
name: termination-demo-container
An alpine container with a command args set to a binary which is not there. Logically the container fails, and we get some telegram messages from kwatch:
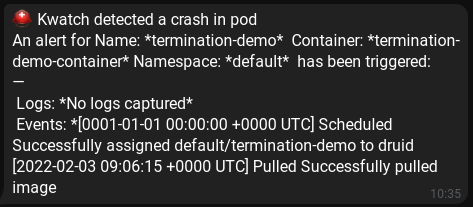
Cert-Manager
Since certificate management is a tedious, unscalable and rather expensive task we'll be using Cert-Manager and Let’s Encrypt certificates to fix all those shortcomings. Cert-Manager simplifies working with in-cluster certificates tremendously by representing the whole certificate workflow as kubernetes objects.
Certificate Creation
The full workflow using cert manager for Let’s Encrypt certificates, including the ACME backend, can be found in the cert-manager documentation. The simplified version with the parts which are relevant to us is as following:
a ingress resource is created with a reference to a tls secret
cert-manager checks if the referenced tls secret is present
if not a certificate request is being created, referencing a Cluster Issuer
the Cluster Issuer creates a new Order
the Order results in a new Challenge
if the Challenge is verified a Certificate Request is created
which finally results in the issue of a Certificate
Certificate Renewal
This is one huge benefit of cert-manager. If we have everything setup like described previously, we don't have to do additional work and get certificate renewal out of the box. The inner workings on how this is automated can be found in the cert-manager documentation.
Installing cert manager
The installation is relatively simply done via the official Helm Chart.
The section in the ansible playbook looks like this:
- name: ensure the cert-manager helm repository is installed
kubernetes.core.helm_repository:
repo_name: jetstack
repo_url: https://charts.jetstack.io
repo_state: present
- name: deploy the cert-manager
kubernetes.core.helm:
name: cert-manager
chart_ref: jetstack/cert-manager
wait: true
kubeconfig: "{{ KUBECONFIG }}"
release_namespace: cert-manager
create_namespace: true
values:
installCRDs: true
The only customizing thats done to the Helm installation is the flag to include CustomResourceDefinitions.
Cloudflare secret
At this points its time to talk about how we authenticate to Letsencrypt that we are even allowed to issue certificates to the domain we want to use. Since i use Cloudflare services for my DNS i will use the cloudflare DNS01 challenge solver for my ownership verification. However there are many more DNS01 and HTTP01 challenge options available. In the simplest terms, this step creates a entity on our end so that the Letsencrypt backend can verify us as owner.
To use the Cloudflare DNS backend we need to create an API key in our Cloudflare Management console which is described here.
The secret resource in the script looks like this:
- name: create cf token
kubernetes.core.k8s:
kubeconfig: "{{ KUBECONFIG }}"
definition:
apiVersion: v1
kind: Secret
metadata:
namespace: cert-manager
name: cloudflare-api-token-secret
type: Opaque
stringData:
api-token: "{{ CF_USER_TOKEN }}"
Deploying a cluster issuer
The last component the setup is lacking now is a Cluster Issuer. It basically serves as an abstraction for the Letsencrypt backend inside our cluster.
- name: create ACME cluster issuer (prod)
kubernetes.core.k8s:
kubeconfig: "{{ KUBECONFIG }}"
definition:
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod
spec:
acme:
email: "{{ ACME_USER_EMAIL }}"
server: "{{ ACME_SERVER }}"
privateKeySecretRef:
name: prod-issuer-account-key
solvers:
- dns01:
cloudflare:
email: "{{ CF_USER_EMAIL }}"
apiTokenSecretRef:
name: cloudflare-api-token-secret
key: api-token
To check the status of our issuer we can describe it via
k describe clusterissuers.cert-manager.io letsencrypt-prod
And it should look like something along those lines
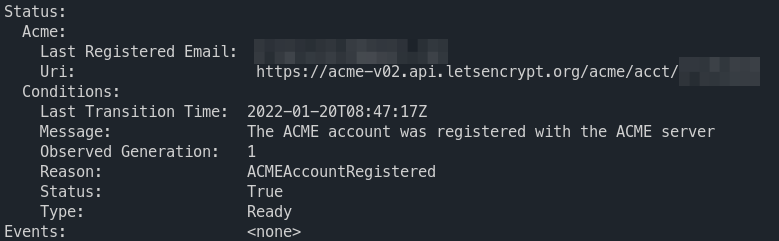
(optional) Creating a certificate
Let's look at an example how it might look like if we want to order a certificate explicitly.
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: dev-wildcard
namespace: dev
spec:
secretName: dev-tls
dnsNames:
- "*.dev.xc-cloud.net"
privateKey:
algorithm: RSA
encoding: PKCS1
size: 4096
usages:
- server auth
issuerRef:
name: letsencrypt-prod
kind: ClusterIssuer
k describe certificate.cert-manager.io speed -n speedtest
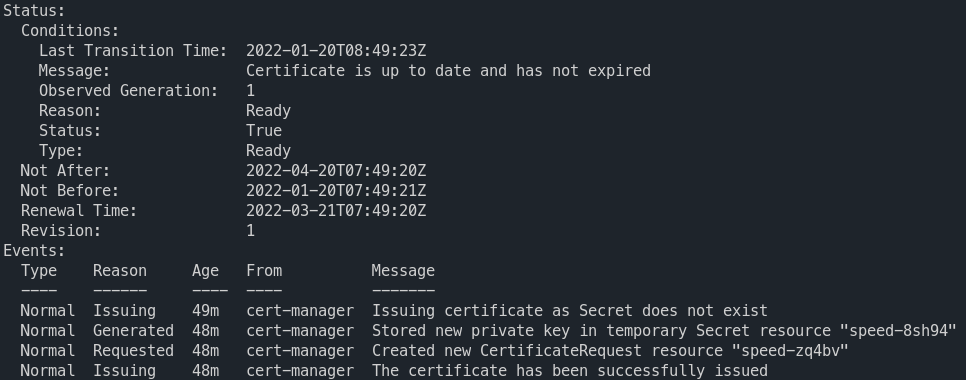
This will create a certificate for us. But we will have to reference it later in our ingresses. This is actually additional work we don't really have to do. It might however be interesting for wildcard certificates who can be used in multiple ingresses.
NFS Persistent Volume Controller
The storage i will be using is NFS based on a QNAP-NAS. To use the NFS Share we utilize the NFS Subdir External Provisioner.
The configuration we give it is relatively straightforward. First we have to make sure the helm chart is enabled and then we deploy the chart with the hostname (nfs.hostname) and the path (nfs.path) of our NFS share. In a enterprise environment you probably will have to include authentication to the NFS share here.
- name: Ensure the nfs-provisioner helm chart is installed
kubernetes.core.helm_repository:
repo_name: nfs-subdir-external-provisioner
repo_url: https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
repo_state: present
- name: Ensure the nfs-provisioner is deployed
kubernetes.core.helm:
name: nfs-subdir-external-provisioner
chart_ref: nfs-subdir-external-provisioner/nfs-subdir-external-provisioner
release_namespace: kube-system
wait: true
kubeconfig: "{{ KUBECONFIG }}"
values:
nfs:
server: "{{ NFS_SERVER_HOST }}"
path: "{{ NFS_SERVER_PATH }}"
This gives us two objects. A external provisioner pod which we don't really have to interact with in any way. More importantly it creates a Storage Class named nfs-client. If we create a Persistent Volume Claim referencing this Storage Class the following happens:
A new folder on the NFS Share is created
A new Persistent Volume in our cluster is created pointing to the folder on the NFS Share
With that all out of the way we can continue to work on porting over our applications, so stay tuned for part two!





